Árvore de Decisão
Árvores de Decisão: Classificação e Regressão
As árvores de decisão são algoritmos de aprendizado supervisionado que podem ser usados tanto para classificação quanto para regressão. Elas funcionam de maneira hierárquica, dividindo os dados em subconjuntos com base em critérios que maximizam a separação entre as classes ou valores previstos. Cada divisão nos dados resulta em um nó na árvore, e os nós folhas representam as predições finais.
Como Funciona uma Árvore de Decisão
O algoritmo cria uma árvore binária que divide os dados com base em perguntas de “sim ou não” (ou condições que podem ser numéricas ou categóricas). O objetivo é dividir os dados de forma que, ao final, cada subconjunto tenha uma maior homogeneidade possível, ou seja, que pertençam a uma mesma classe (para classificação) ou que os valores sejam o mais próximos possível (para regressão).
Classificação
No caso de classificação, o objetivo é separar os dados em grupos distintos com base nas classes disponíveis. Por exemplo, ao classificar se um e-mail é “spam” ou “não spam”, a árvore de decisão usará características do e-mail (tamanho, palavras-chave, etc.) para fazer divisões sucessivas até chegar a uma classificação final.
Regressão
Já na regressão, o algoritmo tenta prever um valor numérico contínuo. Por exemplo, podemos prever o preço de uma casa com base em suas características (tamanho, localização, etc.). A árvore de decisão dividirá o conjunto de dados para minimizar a diferença entre o valor real e o valor previsto.
Construção da Árvore de Decisão
O processo de construção da árvore envolve o seguinte:
-
Seleção do Melhor Atributo: Para cada nó, o algoritmo seleciona o melhor atributo para dividir os dados. O critério de escolha varia entre classificação e regressão.
-
Cálculo da Impureza ou Erro:
- Na classificação, o algoritmo calcula a impureza de um nó usando métricas como a Entropia ou o Índice de Gini.
- Na regressão, ele tenta minimizar o Erro Quadrático Médio (MSE) ou outro erro associado à variância dos dados.
-
Divisão Recursiva: O processo é repetido recursivamente até que os dados estejam completamente separados ou até atingir um critério de parada, como uma profundidade máxima da árvore ou um número mínimo de amostras por nó.
-
Poda: Para evitar o overfitting (quando o modelo se ajusta demais aos dados de treino e perde capacidade de generalização), pode-se utilizar métodos de poda. A poda reduz o tamanho da árvore cortando nós que não agregam valor à predição.
Métricas de Avaliação
Para Classificação:
- Acurácia: Proporção de predições corretas sobre o total de predições.
- Precisão: Proporção de verdadeiros positivos sobre o total de predições positivas feitas pelo modelo.
- Revocação (Recall): Proporção de verdadeiros positivos em relação ao total de exemplos que realmente pertencem àquela classe.
- F1-Score: Média harmônica entre a precisão e a revocação. É útil quando há um desbalanceamento nas classes.
Para Regressão:
- Erro Médio Absoluto (MAE): Média das diferenças absolutas entre os valores preditos e os valores reais.
- Erro Quadrático Médio (MSE): Média das diferenças quadráticas entre os valores preditos e os valores reais.
- R-quadrado ( \(R^2 \)): Medida que indica o quão bem os valores preditos se ajustam aos valores reais.
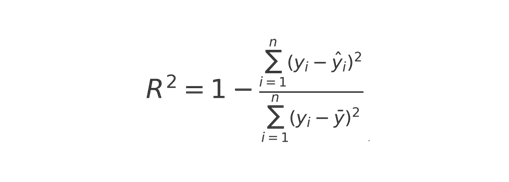
O Parâmetro ccp_alpha (Poda de Custo Complexo)
O parâmetro ccp_alpha é usado para controlar a poda de custo complexo em uma árvore de decisão. A poda é essencial para reduzir o overfitting em árvores muito profundas. O ccp_alpha permite especificar um valor de regularização que penaliza a complexidade da árvore, ou seja, árvores mais simples (com menos nós) são preferidas se o aumento de precisão for pequeno.
A fórmula usada para calcular a penalidade é dada por:
$$ R_\alpha(T) = R(T) + \alpha \cdot \left|T\right| $$Onde:
- \(R(T) \) é o erro da árvore \(T\).
- \(alpha \) é o parâmetro de regularização (
ccp_alpha). - \(\left|T\right|\) é o número de nós na árvore.
Quanto maior o valor de ccp_alpha, mais agressiva será a poda da árvore. Com um valor ccp_alpha = 0, a árvore será a mais complexa possível.
Exemplo Prático em Python
Aqui está um exemplo de como usar árvores de decisão para classificação e regressão, e como aplicar a poda com o parâmetro ccp_alpha:
Classificação
|
|
Regressão
|
|
Casos de Uso
Classificação:
- Diagnóstico Médico: Determinar se um paciente tem uma doença com base em sintomas e exames laboratoriais.
- Detecção de Fraude: Identificar se uma transação bancária é fraudulenta ou não.
Regressão:
- Previsão de Preço de Imóveis: Estimar o preço de uma casa com base em sua localização, tamanho e características.
- Previsão de Demanda: Prever a quantidade de produtos que será vendida em um determinado período.
Conclusão
As árvores de decisão são ferramentas poderosas tanto para classificação quanto para regressão. Embora fáceis de interpretar, sua flexibilidade pode levar ao overfitting. O uso do parâmetro ccp_alpha é fundamental para aplicar poda e melhorar a generalização do modelo.